享元模式(Flyweight Pattern) 前言 在面向对象程序设计过程中,有时会面临要创建大量相同或相似对象实例的问题。创建那么多的对象将会耗费很多的系统资源,它是系统性能提高的一个瓶颈。
定义 享元模式,又称为轻量级模式,运用共享技术来有效地支持大量细粒度对象的复用。它通过共享已经存在的对象来大幅度减少需要创建的对象数量、【宗旨】 :共享细粒度对象,将多个对同一对象的访问集中起来;属于结构性模式;
内部状态和外部状态 在共享对象的过程中,又两种状态:内部状态: 内部状态指对象共享出来的信息,存储在享元信息内部,并且不回随环境的改变而改变;
就是对象所共有的信息,比如火车票,多有从北京-上海的对象可以共用一个,而不是有1000张票,创建1000个对象;
外部状态: 外部状态指对象得以依赖的一个标记,随环境的改变而改变,不可共享;
也是不叫好理解的,当火车票被你购买之后,就和你的身份证号(唯一)绑定了,这属于外部状态;
使用场景 1、常常应用于系统底层的开发,以便解决系统的性能问题;
举个例子🌰 享元实体类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class Examination private String name; private String phone; private String subject; public Examination (String subject) super (); this .subject = subject; } public String getName () return name; } public void setName (String name) this .name = name; } public String getPhone () return phone; } public void setPhone (String phone) this .phone = phone; } @Override public String toString () return "Examination [name=" + name + ", phone=" + phone + ", subject=" + subject + "]" ; } }
享元工厂 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class ExaminationFactory private static Map<String, Examination> pool = new HashMap<>(); public static Examination getexExamination (String name, String phone, String subject) if (pool.containsKey(subject)) { Examination examination = pool.get(subject); examination.setName(name); examination.setPhone(phone); System.out.println("在缓存池取用对象:" + examination.toString()); return examination; } else { Examination examination = new Examination(subject); pool.put(subject, examination); examination.setName(name); examination.setPhone(phone); System.out.println("新建对象:" + examination.toString()); return examination; } } }
测试类 1 2 3 4 5 6 7 8 9 10 11 12 public class Client public static void main (String[] args) Examination A = ExaminationFactory.getexExamination("A" , "13812345678" , "软件工程" ); Examination B = ExaminationFactory.getexExamination("B" , "13812341234" , "软件工程" ); Examination C = ExaminationFactory.getexExamination("C" , "13812341328" , "电子信息工程" ); Examination D = ExaminationFactory.getexExamination("D" , "13812345111" , "桥梁工程工程" ); Examination E = ExaminationFactory.getexExamination("E" , "13812345444" , "软件工程" ); System.err.println(A.hashCode()); System.err.println(B.hashCode()); } }
测试结果 1 2 3 4 5 6 7 新建对象:Examination [name=A, phone=13812345678 , subject=软件工程] 在缓存池取用对象:Examination [name=B, phone=13812341234 , subject=软件工程] 新建对象:Examination [name=C, phone=13812341328 , subject=电子信息工程] 新建对象:Examination [name=D, phone=13812345111 , subject=桥梁工程工程] 在缓存池取用对象:Examination [name=E, phone=13812345444 , subject=软件工程] 1528902577 1528902577
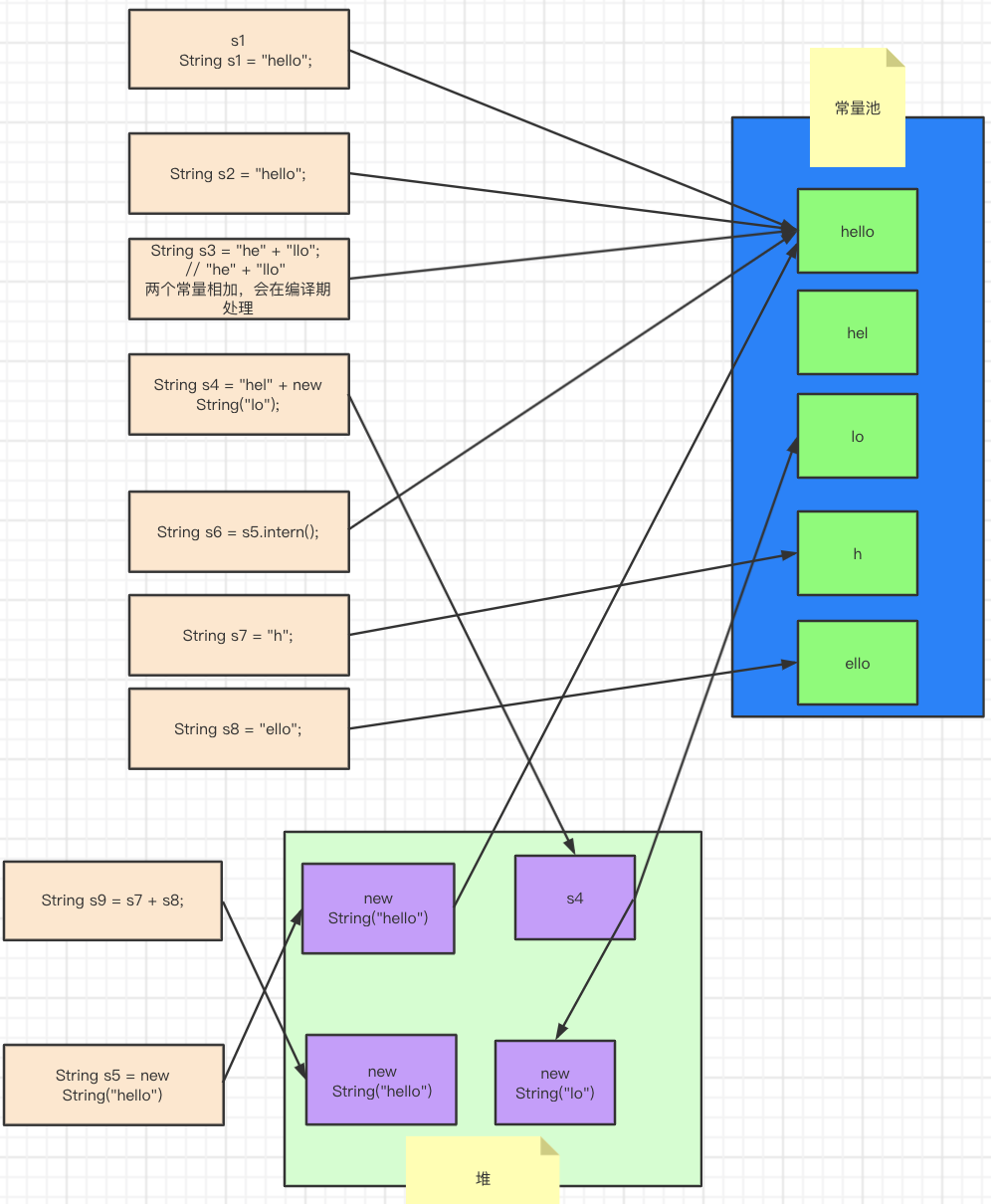
实际应用 1、JDK – String
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static void main (String[] args) String s1 = "hello" ; String s2 = "hello" ; String s3 = "he" + "llo" ; String s4 = "hel" + new String("lo" ); String s5 = new String("hello" ); String s6 = s5.intern(); String s7 = "h" ; String s8 = "ello" ; String s9 = s7 + s8; System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>" ); System.out.println("s1 " + System.identityHashCode(s1)); System.out.println("s2 " + System.identityHashCode(s2)); System.out.println("s3 " + System.identityHashCode(s3)); System.out.println("s4 " + System.identityHashCode(s4)); System.out.println("s5 " + System.identityHashCode(s5)); System.out.println("s6 " + System.identityHashCode(s6)); System.out.println("s7 " + System.identityHashCode(s7)); System.out.println("s8 " + System.identityHashCode(s8)); System.out.println("s9 " + System.identityHashCode(s9)); System.out.print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>" ); System.out.println(s1==s2); System.out.println(s1==s3); System.out.println(s1==s4); System.out.println(s1==s9); System.out.println(s4==s5); System.out.println(s1==s6); }
2、JDK – Integer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private static class IntegerCache static final int low = -128 ; static final int high; static final Integer cache[]; static { int h = 127 ; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high" ); if (integerCacheHighPropValue != null ) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127 ); h = Math.min(i, Integer.MAX_VALUE - (-low) -1 ); } catch ( NumberFormatException nfe) { } } high = h; cache = new Integer[(high - low) + 1 ]; int j = low; for (int k = 0 ; k < cache.length; k++) cache[k] = new Integer(j++); assert IntegerCache.high >= 127 ; } private IntegerCache () }
3、线程池
享元模式的优点✅ 1、减少对象的创建,降低内存中对象的数量,降低系统的内存使用,提升效率;
享元模式的缺点 1、关注内部,外部状态,关注程序线程安全问题;
参考资料 1、[设计模式] - 享元模式 设计模式-享元模式 设计模式-享元设计模式