Flink运行时组件
JobManager (作业管理器)
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:ResourceManager
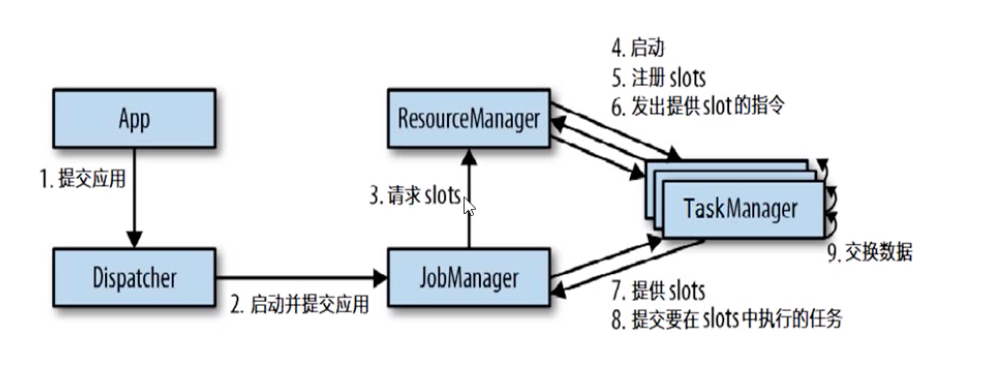
ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理task slots,这是 Flink 集群中资源调度的单位。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。Dispatcher
Dispatcher 提供了一个REST接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。JobMasterJobMaster负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的JobMaster。
始终至少有一个JobManager。高可用(HA)设置中可能有多个JobManager,其中一个始终是 leader,其他的则是standby。
TaskManager (任务管理器)
Flink中的工作进程,通常在flink中会有多个TaskManager运行,每一个TaskMaganer都包含一定数量的插槽(slots). 插槽的数量限制了TaskManager能够执行的任务数量;
启动之后,TaskManager会向资源管理器注册他的插槽,收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用,JobManager就可以向插槽分配任务(tasks)来执行了
在执行的过程中,一个TaskManager可以跟其他运行同一应用程序的TaskManager交换数据。
任务提交流程
任务调度原理
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。

Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程./bin/flink run …中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为standalone 集群启动、在容器中启动、或者通过YARN或Mesos等资源框架管理并启动。TaskManager 连接到 JobManagers,宣布自己可用,并被分配工作。
思考问题🤔
- 怎样实现并行计算? 多线程
- 并行的任务,需要占用多少solt?
- 一个流处理程序,到底包含多少个任务?
Tasks 和算子链
并行度(Parallelism)
一个特定算子的子任务(subtask)的个数被称之为并行度; 一般情况下,一个Stream的并行度就是其所有算子中最大的并行度。
整个流也有一个并行度,就是所有算子所有任务的并行度之和;
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的;请参考链文档以获取详细信息。
TaskManager 和 Slots
