官方地址请戳👉 【传送】
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink 是一个框架和分布式处理器引擎,用于对无界和有界数据进行状态计算;
Why Flink
- 流数据更真实地反应了我们的生活方式
- 传统的数据架构是基于有限数据集的
- 我们的目标
1、低延迟 毫秒级响应
2、高吞吐 能够处理海量数据 分布式
3、结果的准确性和良好的容错性
Where need Flink
- 电商和市场营销
数据报表、广告投放、业务流程需要 - 物联网(IOT)
传感器实时数据采集和显示,实时报警,交通运输业 - 电信业
基站流量调配 - 银行和金融业
实时结算和通知推送、实时检测异常行为
传统数据处理架构
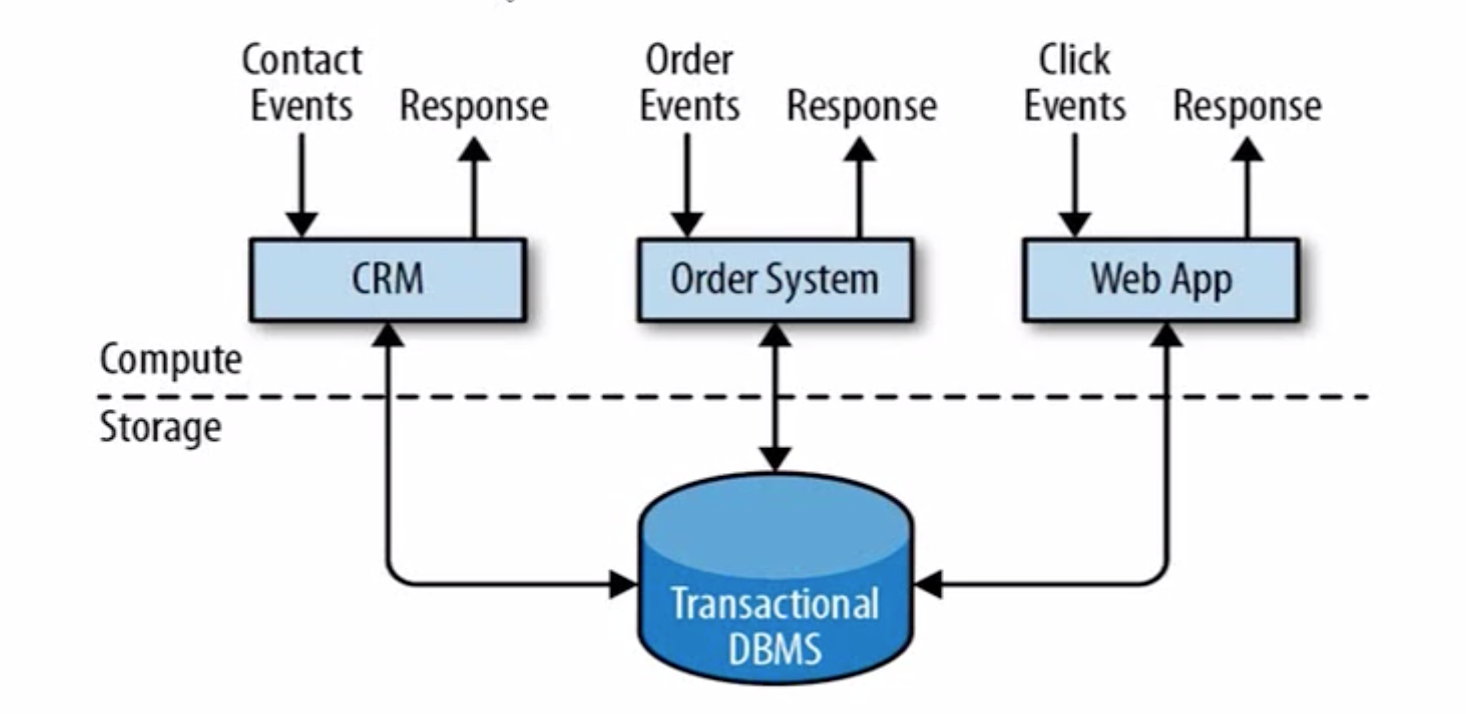
传统的数据处理架构如上👆
CRM(用户关系系统), Order System(订单系统), Web App (用户点击时间),当用户出发行为之后需要系统作出响应,首先由上层的计算层处理计算逻辑,计算层的逻辑计算依赖下面的存储层,计算层计算完成之后,将响应返回给客户端。
这种基于传统数据库方式无法满足高并发场景,数据库的并发量都是很低的。
分析处理流程
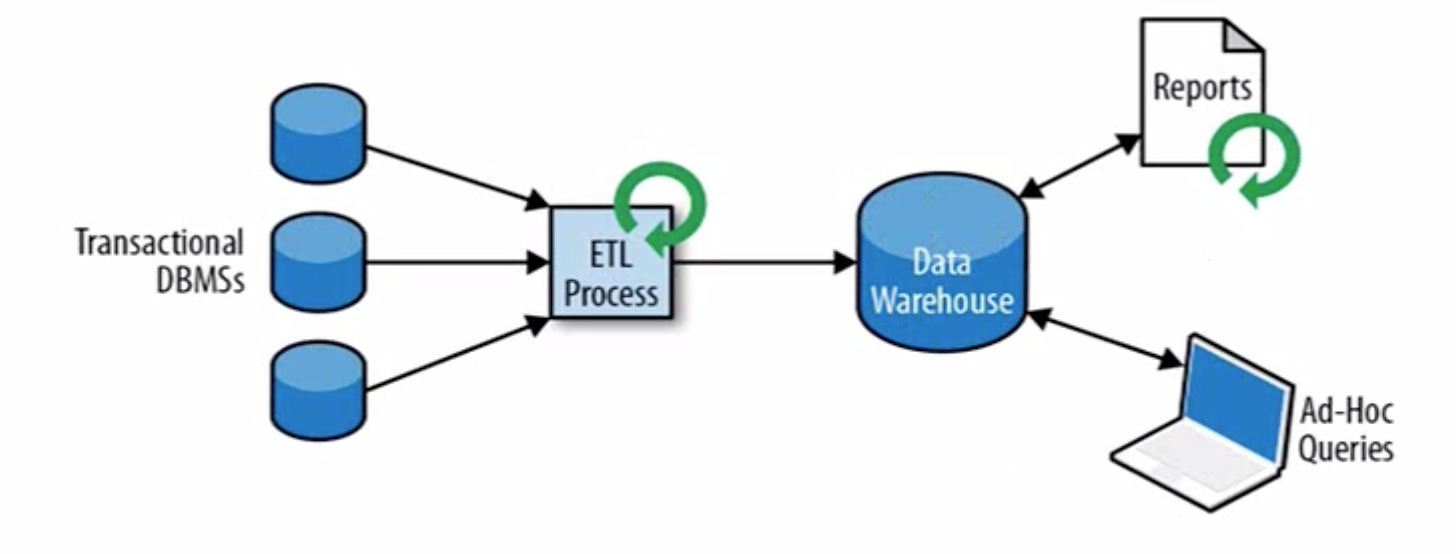 分析处理流程架构如上👆,数据先有传统的关系数据库,经过提取,清洗过滤等,将数据存放到数据仓库,然后通过一些sql处理,生成数据报表和一些其他的查询。
分析处理流程架构如上👆,数据先有传统的关系数据库,经过提取,清洗过滤等,将数据存放到数据仓库,然后通过一些sql处理,生成数据报表和一些其他的查询。
- 问题也很明显,实时性太差了,处理流程太长,无法满足毫秒级需求
- 数据来源不唯一,能满足海量数据和高并发的需求,但是无法满足实时的需求
有状态的流式处理
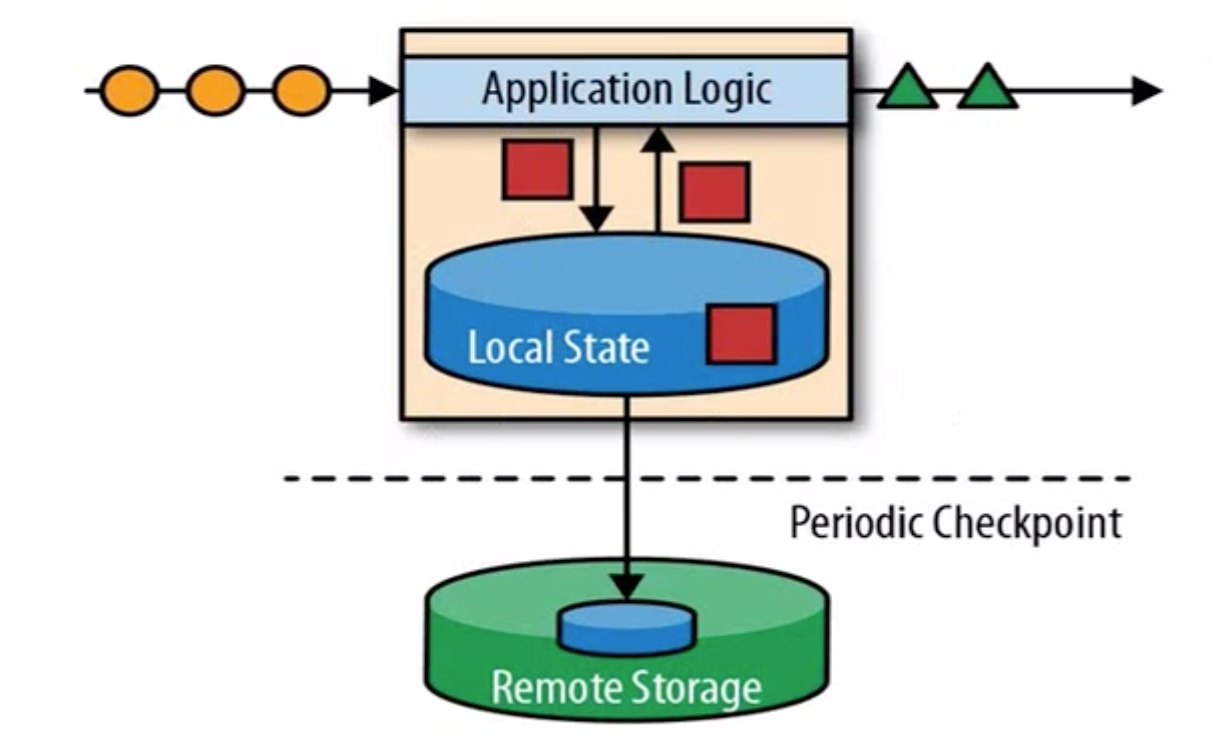 把当前做流式计算所需要的数据不存放在数据库中,而是简单粗暴的直接放到本地内存中;
把当前做流式计算所需要的数据不存放在数据库中,而是简单粗暴的直接放到本地内存中;
内存不稳定?
周期性的检查点,数据存盘和故障检测;
lambda架构
用两台系统同时保障低延迟和结果准确;
- 这套架构分成两个流程,上面为批处理流程,数据收集到一定程序,交给批处理器处理,最终产生一个批处理结果
- 下面的流程为流式处理流程,保证能快速得到结果
- 最终有我们在应用层根据实际问题选择具体的处理结果交给应用程序这种架构有什么缺陷?
可能得到的结果是不准确的,我们可以先快速的得到一个实时计算的结果,隔一段时间之后在来看批处理产生的结果。
实现两台系统和维护两套系统,成本很大;
第三代流式处理架构
Apache Flink 可以完美解决上面的问题👆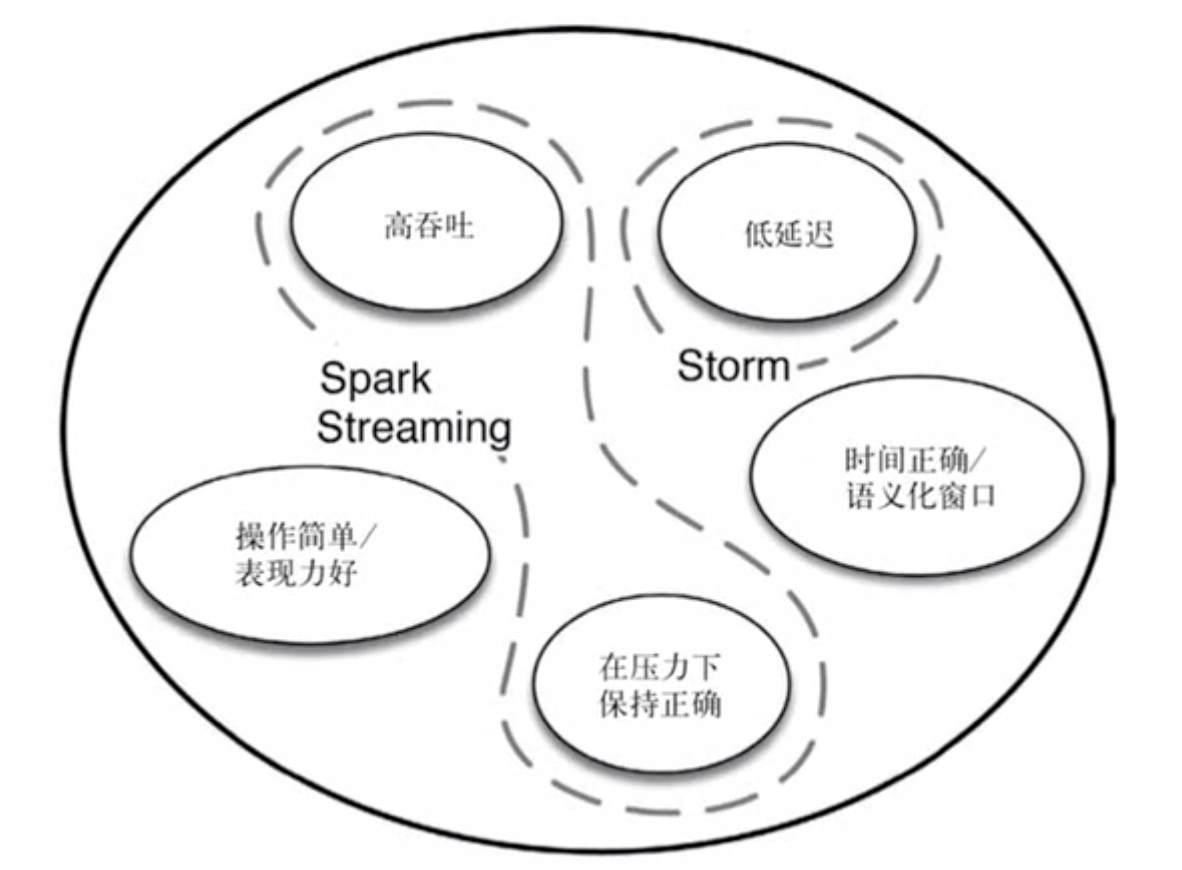
Strom无法满足海量数据; Sparking Stream 无法满足低延迟;
基于事件驱动 (Event-driven)
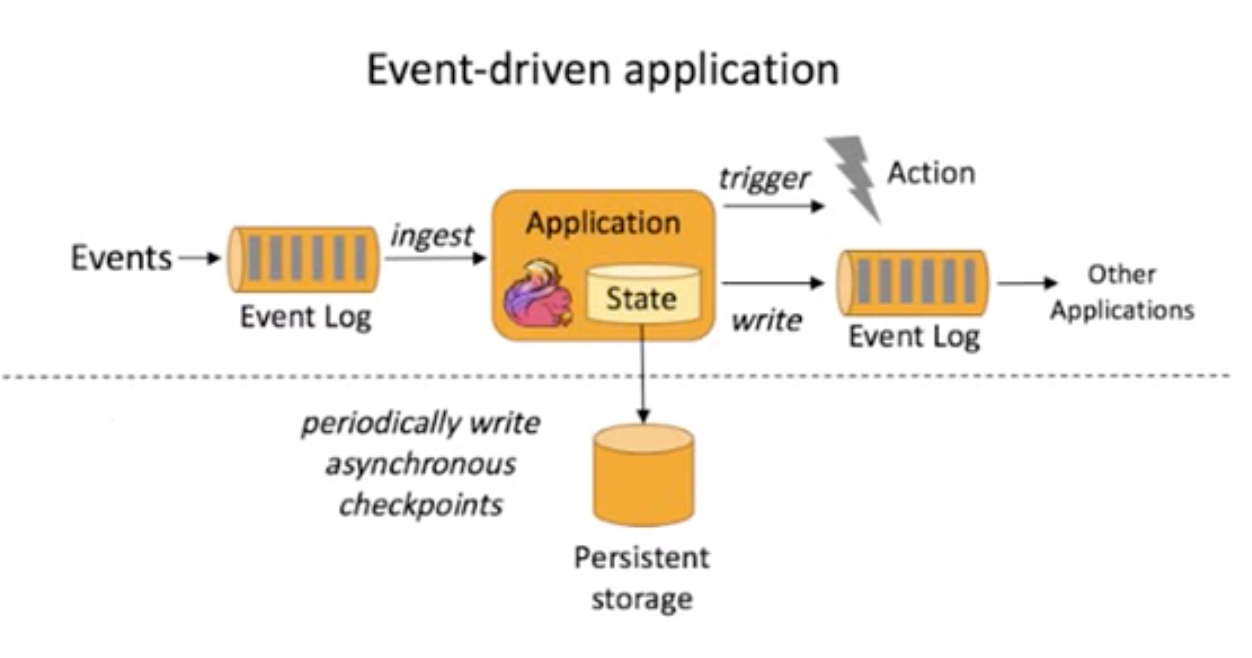
处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流</> 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
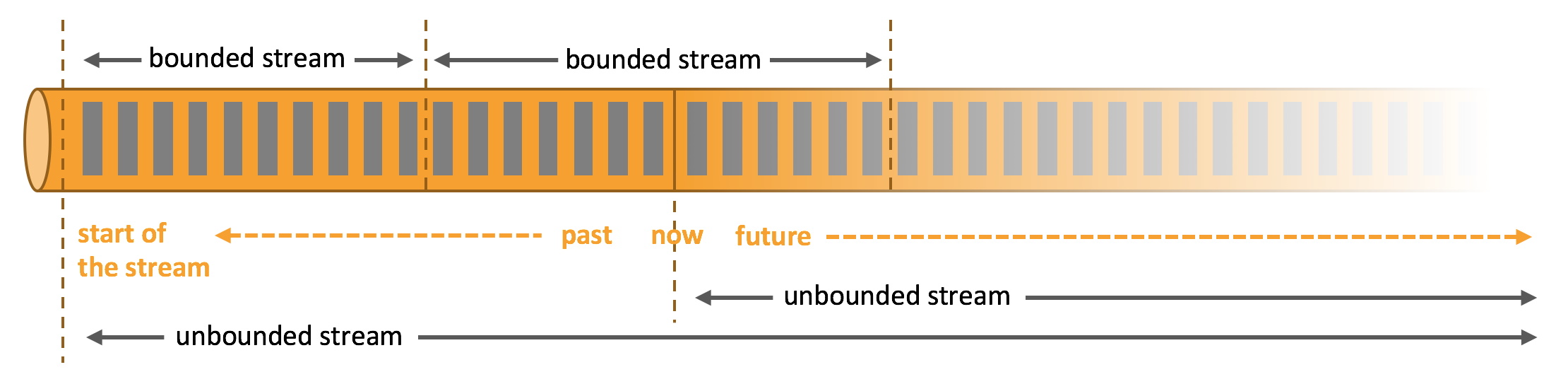
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
其他特点
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次的状态一致性保证
- 低延迟 每秒处理数百万个事件,毫秒级延迟
- 与众多常用的存储系统链接
- 高可用,动态扩展,支持7*24全天运行