Redis之Hash表底层实现
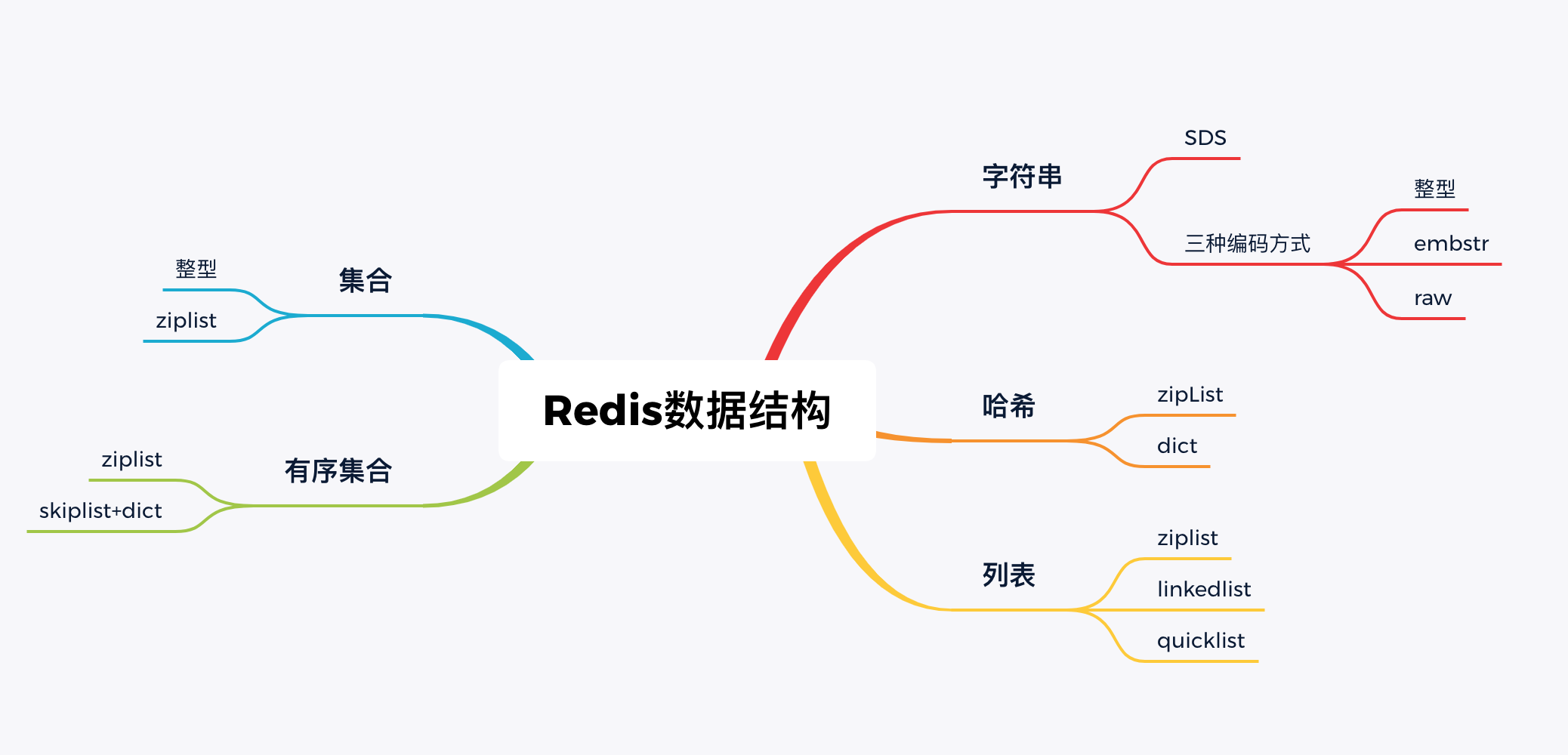
关键词
字段dict | 渐进式哈希 | ziplist | 哈希表
字典底层结构
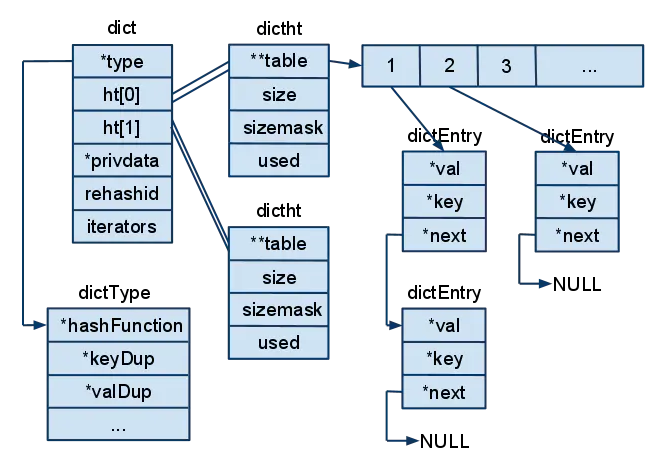
dict 字典结构体
1 | typedf struct dict{ |
- type和private这两个属性是为了实现字典多态而设置的,当字典中存放着不同类型的值,对应的一些复制,比较函数也不一样,这两个属性配合起来可以实现多态的方法调用;
- ht[2],两个hash表
- rehashidx,这是一个辅助变量,用于记录rehash过程的进度,以及是否正在进行rehash等信息,当此值为-1时,表示该dict此时没有rehash过程
- iterators,记录此时dict有几个迭代器正在进行遍历过程
dictht 哈希表结构体
1 | typedf struct dictht{ |
dictEntry 哈希数组结构
1 | typedf struct dictEntry{ |
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。
这里采用的便是链地址法,通过next这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
扩容与缩容
当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
1、如果执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。
相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
2、重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
3、所有键值对都迁徙完毕后,释放原哈希表的内存空间。
触发扩容的条件:
- 1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
- 2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
为什么扩容的时候要考虑BIGSAVE的影响,而缩容时不需要?
- BGSAVE时,dict要是进行扩容,则此时就需要为dictht[1]分配内存,若是dictht[0]的数据量很大时,就会占用更多系统内存,造成内存页过多分离,
所以为了避免系统耗费更多的开销去回收内存,此时最好不要进行扩容; - 缩容时,结合缩容的条件,此时负载因子<0.1,说明此时dict中数据很少,就算为dictht[1]分配内存,也消耗不了多少资源;
渐进式哈希
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,
但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。
所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,
第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行增加操作,一定是在新的哈希表上进行的。
- 渐进式哈希其实就是慢慢的,一步一步的将hash表的数据迁移到另一个hash表中
- redis会有一个定时任务去检测是否需要进行rehash
- rehash的过程中会在字典dict中维护一个rehashidx的标志
- 在rehash的过程中,两个hash表中都会有数据,此时如果有数据新增,将会存在ht[1]也就是第二个哈希表上;
- 在rehash的过程中,如果有删改查,则优先选择第一张表,如果第一张表没有查到数据,则查找第二章哈希表;
参考资料
1、Redis详解(四)—— redis的底层数据结构
2、Redis底层数据结构之hash
3、Redis Hash数据结构的底层实现
4、图解redis五种数据结构底层实现(动图哦)
5、redis hash底层数据结构
6、Redis底层数据结构之hash