用了那么久MySQL,我竟然不知道ICP
概述
开启ICP,如果部分WHERE条件能使用索引中的字段,MySQL Server 会把这部分下推到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出。ICP能减少引擎层访问基表的次数和MySQL Server 访问存储引擎的次数。
ICP 优化的全称是 Index Condition Pushdown Optimization 。
ICP 优化适用于 MySQL 利用索引从表里检索数据的场景。
经过学习了ICP之后我大概对ICP有了初步的理解 👇
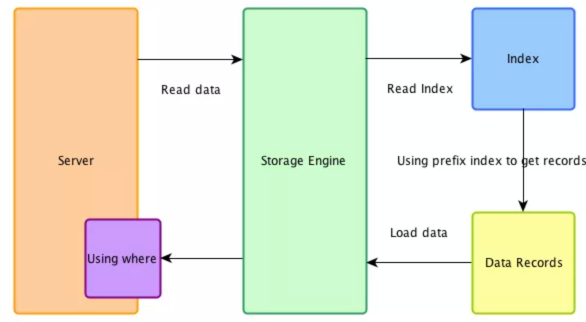
关闭ICP情况下的查询流程
禁用ICP,存储引擎会通过遍历索引定位基表中的行,然后返回给MySQL Server层,再去为这些数据行进行WHERE后的条件的过滤。
开启ICP之后的执行流程
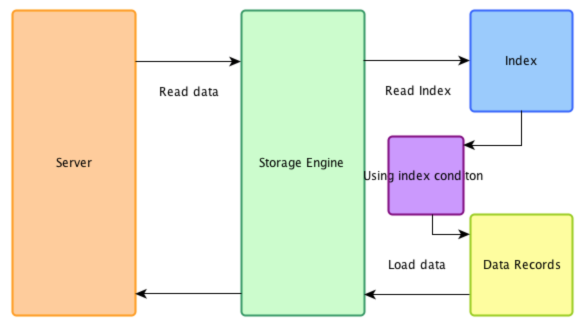
一开始我对于 ICP只能使用于二级索引,而不能用于主键索引这一限制不太理解。那是因为我没有该明白ICP到底是干什么的?
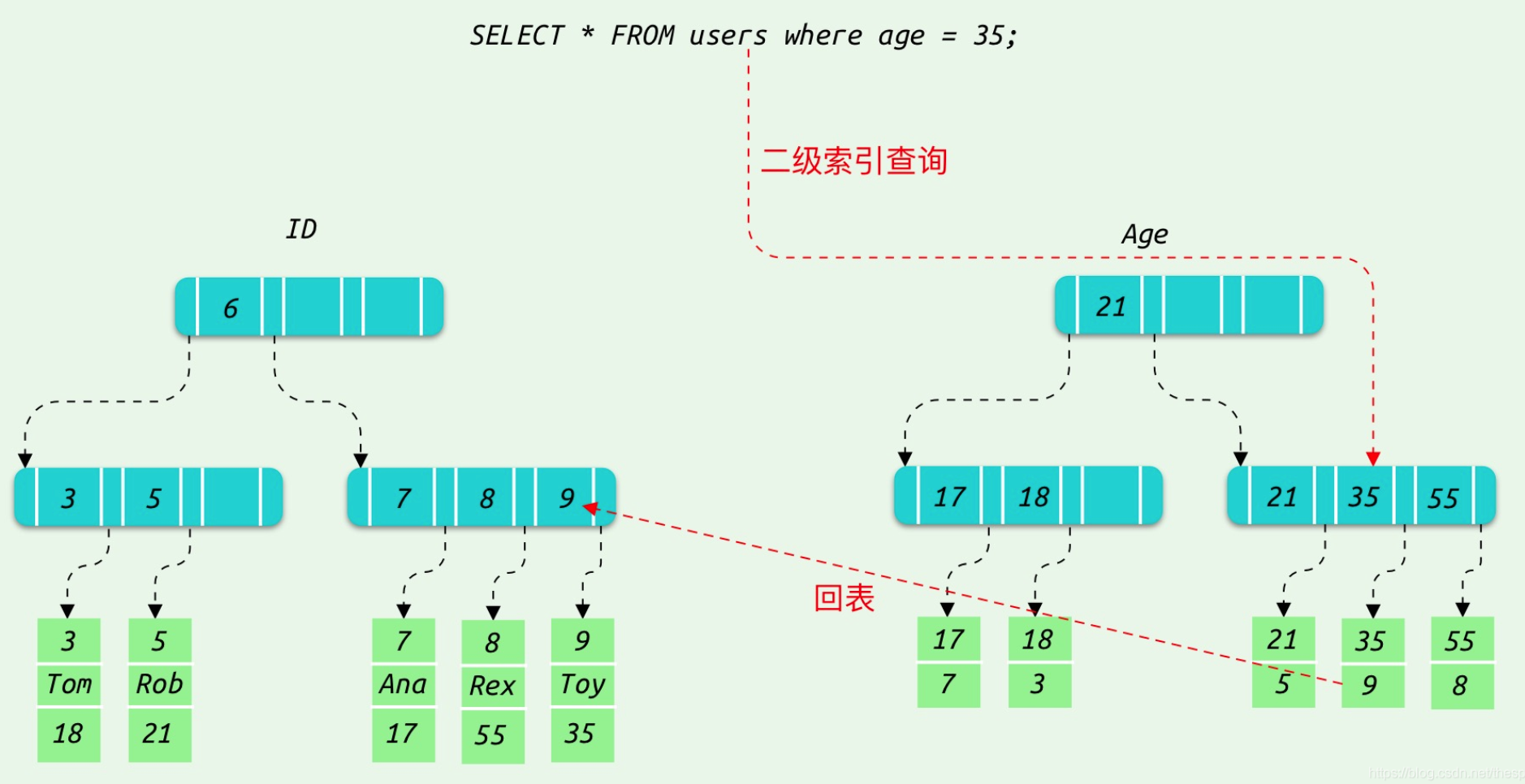
我们这边用一些别人的图方便理解。
ICP能减少引擎层访问基表的次数和MySQL Server 访问存储引擎的次数。
这是ICP的关键目的,为什么能减少引擎对于基表的访问呢?因为ICP在引擎层执行了额外的过滤和筛选,使得大量的无效数据查询基表。
因为是二级索引,需要根据主键id去获取到整行的数据。
ICP 原理
以 InnoDB 表为例。
在不启用 ICP 的情况下利用二级索引查找数据的过程:
- 用二级索引查找数据的主键;
- 用主键回表读取完整的行记录;
- 利用 where 语句的条件对行记录进行过滤。
启用 ICP 的情况下利用二级索引查找数据的过程为:
- 用二级索引查找数据的主键;
- 如果二级索引记录的元组里的列出现在 where 条件里,那么对元组进行过滤;
- 对索引元组的主键回表读取完整的行记录;
- 利用 where 语句的剩余条件对行记录进行过滤;
ICP 适用的一个隐含前提是二级索引必须是组合索引、且在使用索引进行扫描时只能采用最左前缀匹配原则。组合索引后面的列出现在 where 条件里,因此可以先过滤索引元组、从而减少回表读的数量。
举例
对于组合索引 INDEX (zipcode, lastname, firstname),下面的 SQL 根据最左前缀原则,只能使用到索引的第一列 zipcode,索引的另一列 lastname 出现在 where 条件里,可以采用 ICP 对索引的元组进行过滤,即应用 lastname LIKE '%etrunia%' 条件;然后再回表读取完成的行记录,再对行记录应用 address LIKE '%Main Street%' 条件。
1 | SELECT * FROM people |
ICP使用限制
1 当sql需要全表访问时,ICP的优化策略可用于range, ref, eq_ref, ref_or_null 类型的访问数据方法 。
2 支持InnoDB和MyISAM表。
3 ICP只能用于二级索引,不能用于主索引。
4 并非全部where条件都可以用ICP筛选。
如果where条件的字段不在索引列中,还是要读取整表的记录到server端做where过滤。
5 ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例。
6 5.6 版本的不支持分表的ICP 功能,5.7 版本的开始支持。
7 当sql 使用覆盖索引时,不支持ICP 优化方法。
如何查看是否开启了ICP
show variables like 'optimizer_switch';
1 | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on |
什么是二级索引
1、一级索引
索引和数据存储在一起,都存储在同一个B+tree中的叶子节点。一般主键索引都是一级索引。
2、二级索引
二级索引树的叶子节点存储的是主键而不是数据。也就是说,在找到索引后,得到对应的主键,再回到一级索引中找主键对应的数据记录。
参考文档
https://mp.weixin.qq.com/s/ygvuP35B_sJAlBHuuEJhfg
https://mp.weixin.qq.com/s/Vv1gNLh1aLCLDJfEYXvr-g