Innodb架构
存储引擎是MySQL非常重要的组成部分,它直接影响了一个数据库的性能,是MySQL的绝对核心。
下面是InnoDB的结构图 👇
从上面第二张图可以看到,InnoDB 主要分为两大块:
- InnoDB In-Memory Structures
- InnoDB On-Disk Structures
内存和磁盘,让我们先从内存开始。
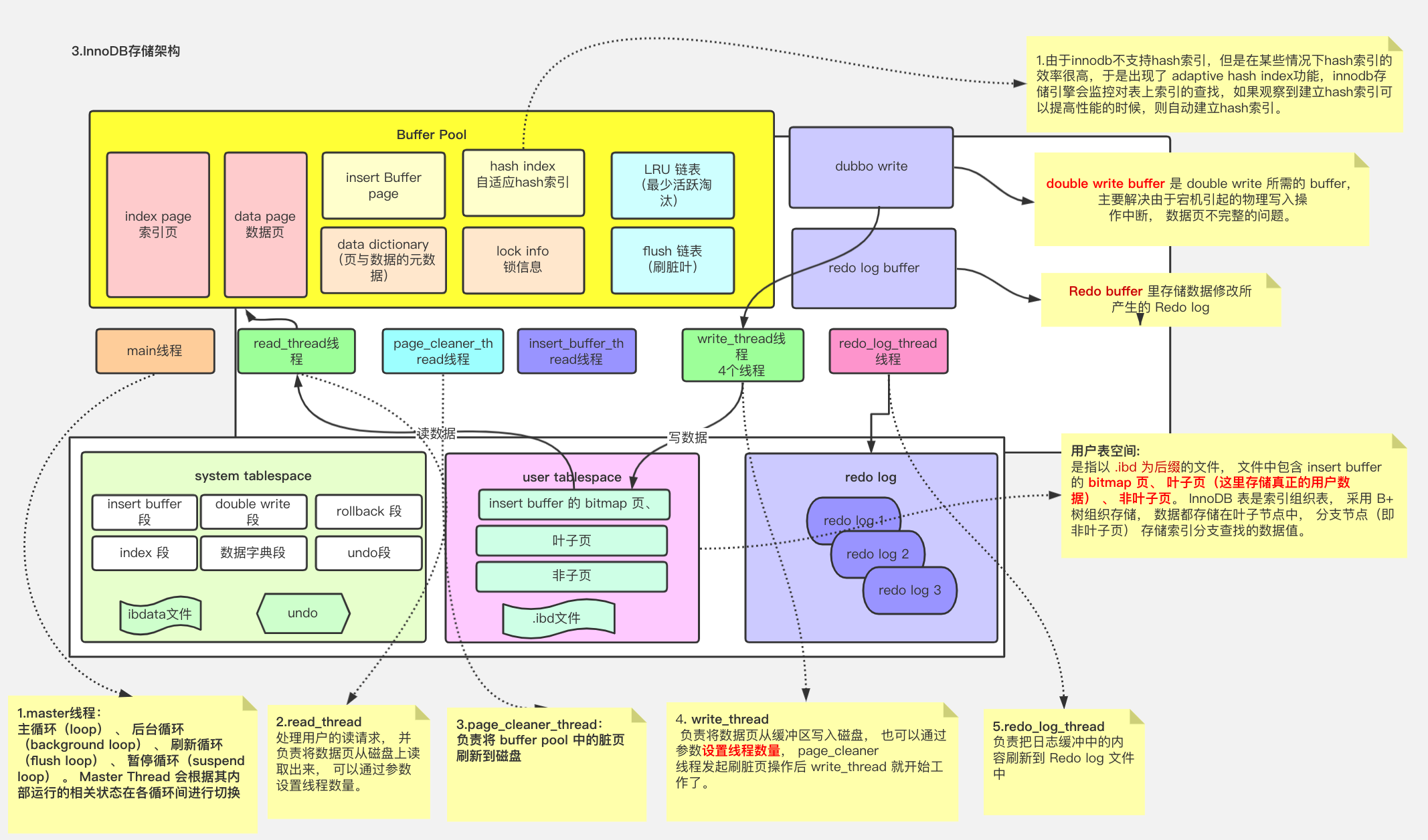
In-Memory Structures内存模块
Buffer Pool
正如之前提到的,MySQL 不会直接去修改磁盘的数据,因为这样做太慢了,MySQL 会先改内存,然后记录 redo log,等有空了再刷磁盘,如果内存里没有数据,就去磁盘 load。
而这些数据存放的地方,就是 Buffer Pool。
我们平时开发时,会用 redis 来做缓存,缓解数据库压力,其实 MySQL 自己也做了一层类似缓存的东西。
MySQL 是以「页」(page)为单位从磁盘读取数据的,Buffer Pool 里的数据也是如此,实际上,Buffer Pool 是a linked list of pages,一个以页为元素的链表。
为什么是链表?因为和缓存一样,它也需要一套淘汰算法来管理数据。Buffer Pool 采用基于 LRU(least recently used) 的算法来管理内存。
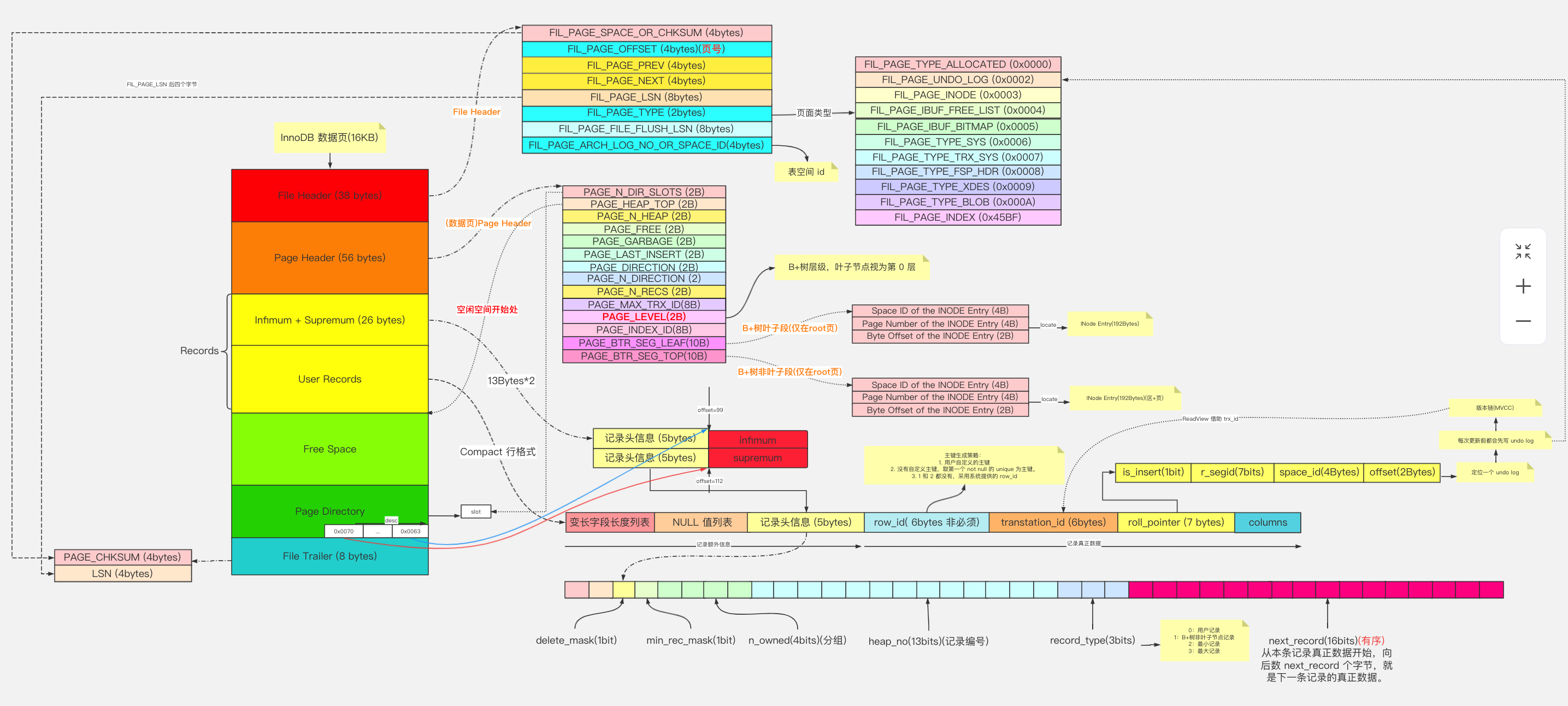
B+树中一个节点为一页或页的倍数最为合适。为什么呢?
因为如果一个节点的大小小于1页,那么读取这个节点的时候其实也会读出1页,造成资源的浪费。
如果一个节点的大小大于1页,比如1.2页,那么读取这个节点的时候会读出2页,也会造成资源的浪费。
所以为了不造成浪费,所以最后把一个节点的大小控制在1页、2页、3页、4页等倍数页大小最为合适。
- 各个数据页可以组成一个双向链表
- 而每个数据页中的记录又可以组成一个单向链表
- 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
所以说,如果我们写 select * from user where username=’小明’ 这样没有进行任何优化的sql语句,默认会这样做:
- 定位到记录所在的页
- 需要遍历双向链表,找到所在的页
- 从所在的页内中查找相应的记录
- 由于不是根据主键查询,只能遍历所在页的单链表了
Change Buffer
change buffer存放在Buffer Pool中。
上面提到过,如果内存里没有对应「页」的数据,MySQL 就会去把数据从磁盘里 load 出来,如果每次需要的「页」都不同,或者不是相邻的「页」,那么每次 MySQL 都要去 load,这样就很慢了。
于是如果 MySQL 发现你要修改的页,不在内存里,就把你要对页的修改,先记到一个叫 Change Buffer 的地方,同时记录 redo log,然后再慢慢把数据 load 到内存,load 过来后,再把 Change Buffer 里记录的修改,应用到内存(Buffer Pool)中,这个动作叫做 merge;而把内存数据刷到磁盘的动作,叫 purge:
- merge:Change Buffer -> Buffer Pool
- purge:Buffer Pool -> Disk
Adaptive Hash Index
MySQL 索引,不管是在磁盘里,还是被 load 到内存后,都是 B+ 树,B+ 树的查找次数取决于树的深度。你看,数据都已经放到内存了,还不能“一下子”就找到它,还要“几下子”,这空间牺牲的是不是不太值得?
尤其是那些频繁被访问的数据,每次过来都要走 B+ 树来查询,这时就会想到,我用一个指针把数据的位置记录下来不就好了?
这就是「自适应哈希索引」(Adaptive Hash Index)。自适应,顾名思义,MySQL 会自动评估使用自适应索引是否值得,如果观察到建立哈希索引可以提升速度,则建立。
Redo log buffer
Redo log buffer里面存储了数据修改所产生的redo log。
On-Disk Structures 磁盘模块
磁盘里有什么呢?除了表结构定义和索引,还有一些为了高性能和高可靠而设计的角色,比如 redo log、undo log、Change Buffer,以及 Doublewrite Buffer 等等.
Tablespaces表空间
Tablespaces 分为五种:
- The System Tablespace
- File-Per-Table Tablespaces
- General Tablespace
- Undo Tablespaces
- Temporary Tablespaces
其中,我们平时创建的表的数据,可以存放到 The System Tablespace 、File-Per-Table Tablespaces、General Tablespace 三者中的任意一个地方,具体取决于你的配置和创建表时的 sql 语句。
Doublewrite Buffer
如果说 Change Buffer 是提升性能,那么 Doublewrite Buffer 就是保证数据页的可靠性。
怎么理解呢?
前面提到过,MySQL 以「页」为读取和写入单位,一个「页」里面有多行数据,写入数据时,MySQL 会先写内存中的页,然后再刷新到磁盘中的页。
这时问题来了,假设在某一次从内存刷新到磁盘的过程中,一个「页」刷了一半,突然操作系统或者 MySQL 进程奔溃了,这时候,内存里的页数据被清除了,而磁盘里的页数据,刷了一半,处于一个中间状态,不尴不尬,可以说是一个「不完整」,甚至是「坏掉的」的页。
有同学说,不是有 Redo Log 么?其实这个时候 Redo Log 也已经无力回天,Redo Log 是要在磁盘中的页数据是正常的、没有损坏的情况下,才能把磁盘里页数据 load 到内存,然后应用 Redo Log。而如果磁盘中的页数据已经损坏,是无法应用 Redo Log 的。
所以,MySQL 在刷数据到磁盘之前,要先把数据写到另外一个地方,也就是 Doublewrite Buffer,写完后,再开始写磁盘。Doublewrite Buffer 可以理解为是一个备份(recovery),万一真的发生 crash,就可以利用 Doublewrite Buffer 来修复磁盘里的数据。
Insert Buffer
对于主键顺序插入的数据,插入速度很快,因为数据页的存放是按照主键顺序存放的。但是对于非聚集的且不是唯一的索引,数据的插入不是连续的,所以需要离散的访问非聚集索引页,随机读取的存在会导致插入操作性能下降。
MySQL 的插入缓冲,在非聚集索引的插入或更新时,不直接插入到索引页,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;如果不在,不会去读数据,而是先放入到一个insert buffer对象中,然后再以一定的频率和情况进行 insert buffer 和 辅助索引页子节点合并操作,这是通常能将多个插入合并到一个操作中,这就大大提高了对于非聚集索引插入的性能。
使用Insert Buffer的场景
1、索引是辅助索引
2、索引不是唯一的
因为在插入时,数据库并不去查找插入记录的唯一性,否则就需要离散的读取数据,这使 insert buffer 失去了意义。
风险点
如果数据库宕机时还有大量的缓存没合并到实际的索引中去,恢复这些数据可能需要很长的时间
flush neighbor page
当刷新一个脏页时,Innodb存储引擎会 检测该页所在区的所有页,如果是脏页,那么一起进行刷新
innodb_fast_shutdown参数
innodb_fast_shutdown参数有三个值 如下👇
0 表示mysql数据库关闭时,innodb需要完成所有的full purge 和 merge insert buffer,并将所有的脏页刷新会磁盘。耗时长
1 默认值,表示不需要完成 full purge 和 merge insert buffer 操作,但是在缓冲池中的一些数据还是会刷新会磁盘。
2 表示不完成 full purge 和 merge insert buffer 操作,也不刷新脏页,而是将日志都写入日志。这样不会有任何的事务丢失,但是下次数据库启动时,需要进行恢复操作
后台线程
InnoDB 是多线程模型,不同的后台线程处理不同的任务。
Master Thread
核心线程,负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲、Undo页的回收。
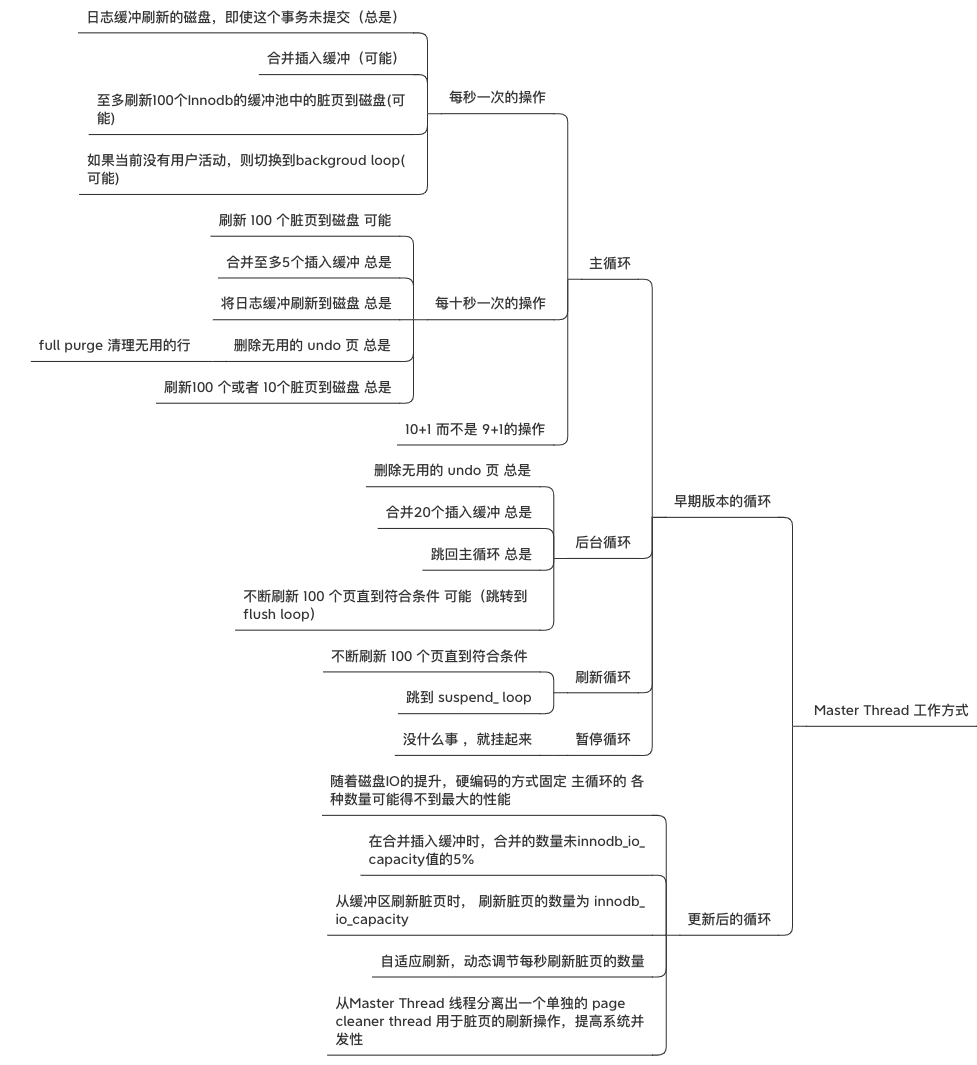
IO Thread
InnoDB 使用AIO处理IO请求,提高数据库性能,IO Thread负责这些请求的回调。
IO Thread 包括write/read/insert buffer/log io thread
Purge Thread
事务被提交后,其使用的undolog可能不再需要,需要 purge thread来回收已经使用并分配的undo页
Page Cleaner Thread
减轻原Master Thrad 的工作及对于用户查询线程的阻塞,进一步提供InnoDB存储引擎的性能
checkpoint
什么是checkpoint
页面操作先在内存缓冲区,再刷新到磁盘,如果刷新磁盘时发生的宕机,那么数据将丢失。为了解决这个文件,当前事务数据库普遍使用 write ahead log策略,即事务提交时,先写重做日志,再修改页。这样即使宕机,也可以通过重做日志来完成数据的恢复。但是重做日志没有redis的redo功能,对于运行时间较长或者提交较大的重做日志恢复是非常耗时的,所以需要 CheckPoint 解决
Checkpoint 解决的问题
1、缓冲池不够用时 ,将脏页刷新到磁盘
2、重做日志不可用时,刷新脏页
3、数据库只需要到checkpoint后的日志进行恢复,缩短数据库的恢复时间