Java内存模型
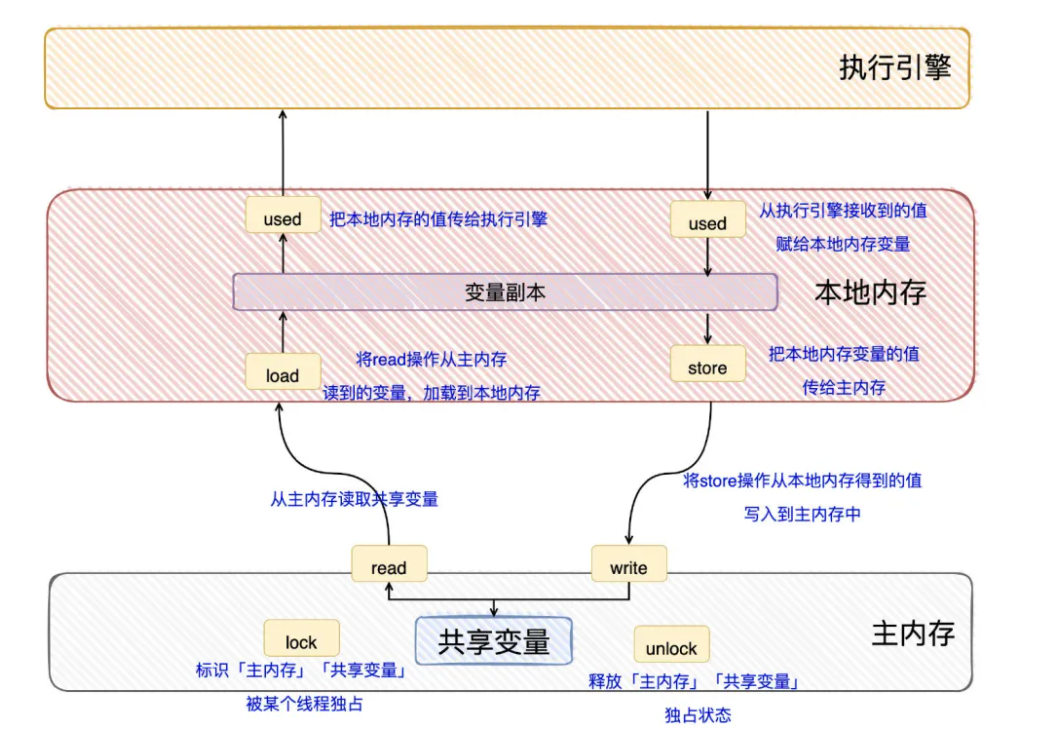
什么是JMM?
Java Memory Model简称JMM, 是一系列的Java虚拟机平台对开发者提供的多线程环境下的内存可见性、是否可以重排序等问题的无关具体平台的统一的保证。(可能在术语上与Java运行时内存分布有歧义,后者指堆、方法区、线程栈等内存区域)。
JMM规范的内容
- 所有变量存储在主内存
- 主内存是虚拟机内存的一部分
- 每条线程有自己的工作内存
- 线程的工作内存保存变量的主内存副本
- 线程对变量的操作必须在工作内存中进行
- 不同线程之间无法直接访问对方工作内存中的变量
- 线程间变量值的传递均需要通过主内存来完成
JMM并不是一个客观存在的东西,它实际是为了规范Java虚拟机制定到一套标准。那为什么需要这套标准呢?
其实我们都知道JVM是运行在操作系统之上的。而目前的操作系统都是基于冯诺伊曼设置的计算机系统体系来的。CPU是计算机中用来执行控制和计算的核心组件。
所有的计算任务全部在CPU中完成,但是我们的所有变量的数据全部存储在主内存中。CPU在执行计算时,需要去主内存加载数据,CPU执行运算的速度极快,这就设计一个CPU执行速度和数据加载速度不一致的问题。
在操作系统级别解决这个问题的办法是引入了CPU缓存。每个CPU都有自己私有的L1缓存和L2缓存,当执行计算时,会优先去CPU自己的缓存中寻找数据,没有的话才会重新加载内存数据。这种方式一定程度上解决了CPU计算和数据加载不一致的问题。
但是也会引入一个新的问题,就是数据一致性问题。
缓存一致性与MESI协议
首先看一下什么是MESI协议
缓存一致性协议给缓存行(通常为64字节)定义了个状态:独占(exclusive)、共享(share)、修改(modified)、失效(invalid),
用来描述该缓存行是否被多处理器共享、是否修改。所以缓存一致性协议也称MESI协议。
- 独占(exclusive):仅当前处理器拥有该缓存行,并且没有修改过,是最新的值。
- 共享(share):有多个处理器拥有该缓存行,每个处理器都没有修改过缓存,是最新的值。
- 修改(modified):仅当前处理器拥有该缓存行,并且缓存行被修改过了,一定时间内会写回主存,会写成功状态会变为S。
- 失效(invalid):缓存行被其他处理器修改过,该值不是最新的值,需要读取主存上最新的值。
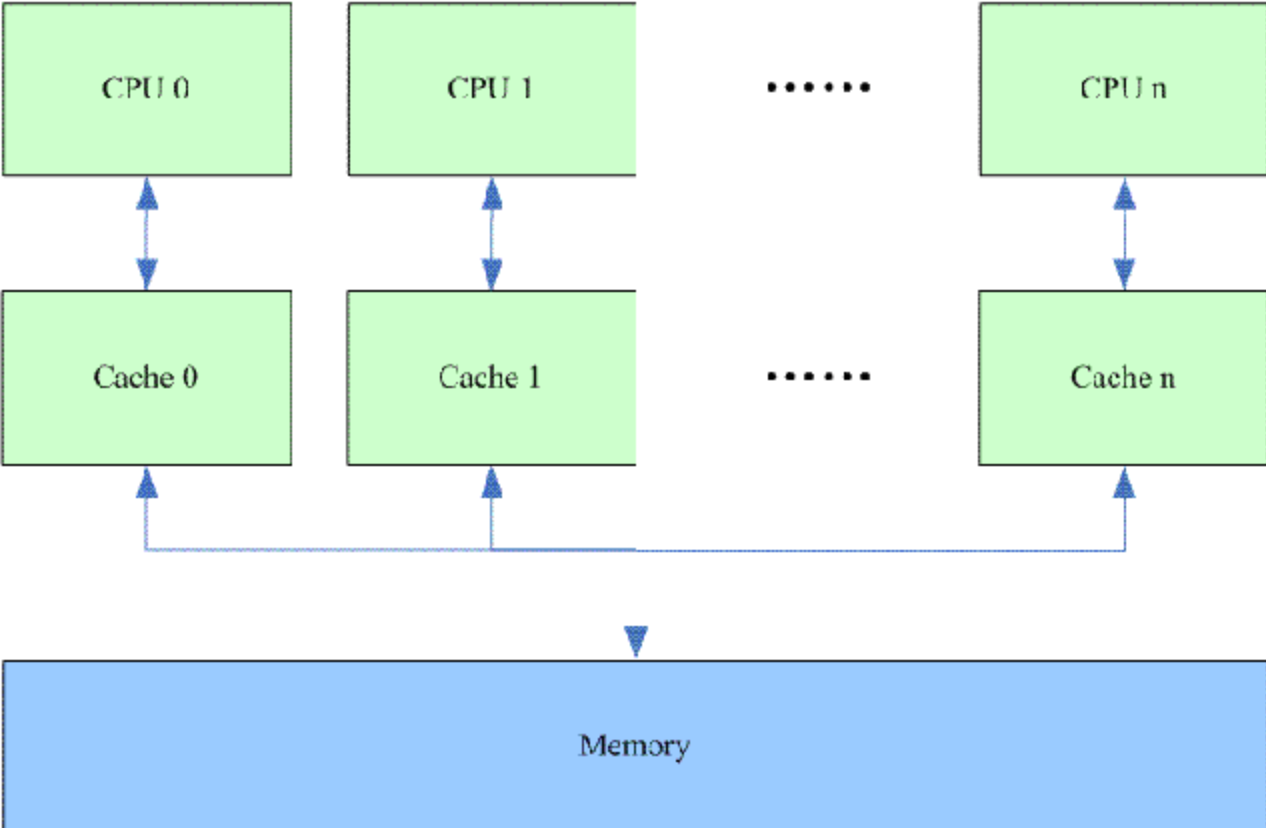
如何解决缓存一致性问题呢?
如上图所示,共享变量是存储在主内存Memory中,在CPU计算时,每一个CPU都有改变量的独立拷贝,每个CPU可以去读取甚至修改共享变量的值,但是为了保证数据的一致性,一个CPU modify了变量的值,需要通知其他的CPU这个变量的最新值是什么。那么可以怎么做呢。
1、在初始状态,每个CPU还没有加载共享变量,所有每一个CPU的缓存行的状态都是invalid;
2、当CPU0去使用这个共享变量的时候,首先去自己的缓存中查找,肯定是缓存不命中的,也就是cache miss,这个时候去主内存Memory中去加载,当共享变量的值加载到CPU0的缓存后,CPU缓存行状态变成shared, 也就是共享状态;
3、如果这个时候有其他的CPU也读取了共享变量的值,它们的cache line 的状态同样也是shared共享状态;此时一个CPU如果修改共享变量的值,而没有通知其他的CPU,就会造成缓存一致性问题;
4、当CPU0尝试去修改共享变量的值时,它会发出一个read invalidate命令,同时CPU0的缓存行状态设置为exclusive(独占),同时将其他加载了这个共享变量的cacheline的状态设置为invalid。通俗一点就是CPU0独占的这个变量的缓存行,其他的CPU缓存的共享变量都失效了;
5、CPU0接下来修改共享变量的值,它会将cacheline的状态修改为modified,其实也是独占共享变量的cacheline,
只不过是此时缓存行的数据和主内存Memory的数据不一致的,而exclusive虽然也是独占状态,但是共享变量的值是一样的,modified的值需要write back到Memory中去的,而exclusive是不需要的;
6、在cacheline没有替换出CPU0的cache之前,当有其他CPU来读取共享变量,此时肯定是cache miss ,因为CPU0的modify操作已经将它的缓存失效了。如果CPU0的状态是modified状态,它必须响应其他CPU的读操作,会告知其他CPU主内存的数据是dirty data。所以其他的CPU的状态可能会变成shared。如果CPU0还没有write back操作,其他的CPU状态还是invalid状态。
Store Buffer
正如上面所描述的,在CPU0进行共享变量的修改,会同步修改其他CPU的cacheline状态为invalid,这个操作是和共享变量的写操作同步进行的,因此共享变量的写操作的性能是非常差的。在修改其他的CPU cacheline状态时,CPU0其实是处于阻塞状态的。所以为了优化这个问题,提出了Store Buffer的解决方案。
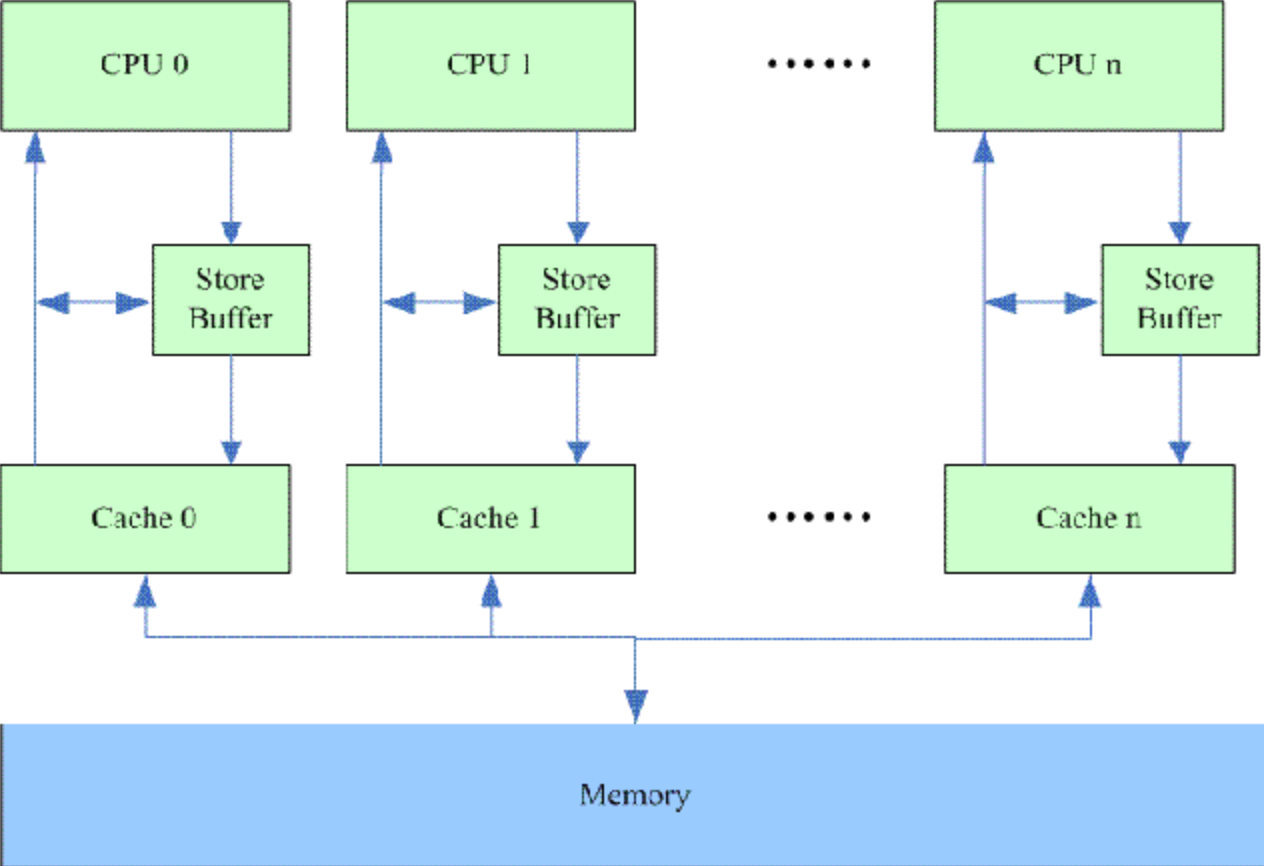
这样的话,写操作不必等到cacheline被加载,而是直接写到store buffer中,然后去执行后续的操作。由于是store buffer相当于是异步处理,在这里可能会出现因为并发执行导致的执行执行交叉问题,具体解决方法是依赖于内存屏障。
具体可以参考这篇文章:Linux内核同步机制之(三):memory barrier
Invalidate Queue
处理失效的缓存也不是简单的,需要读取主存。并且存储缓存也不是无限大的,那么当存储缓存满的时候,处理器还是要等待失效响应的。为了解决上面两个问题,引进了失效队列(invalidate queue)。
处理失效的工作如下:
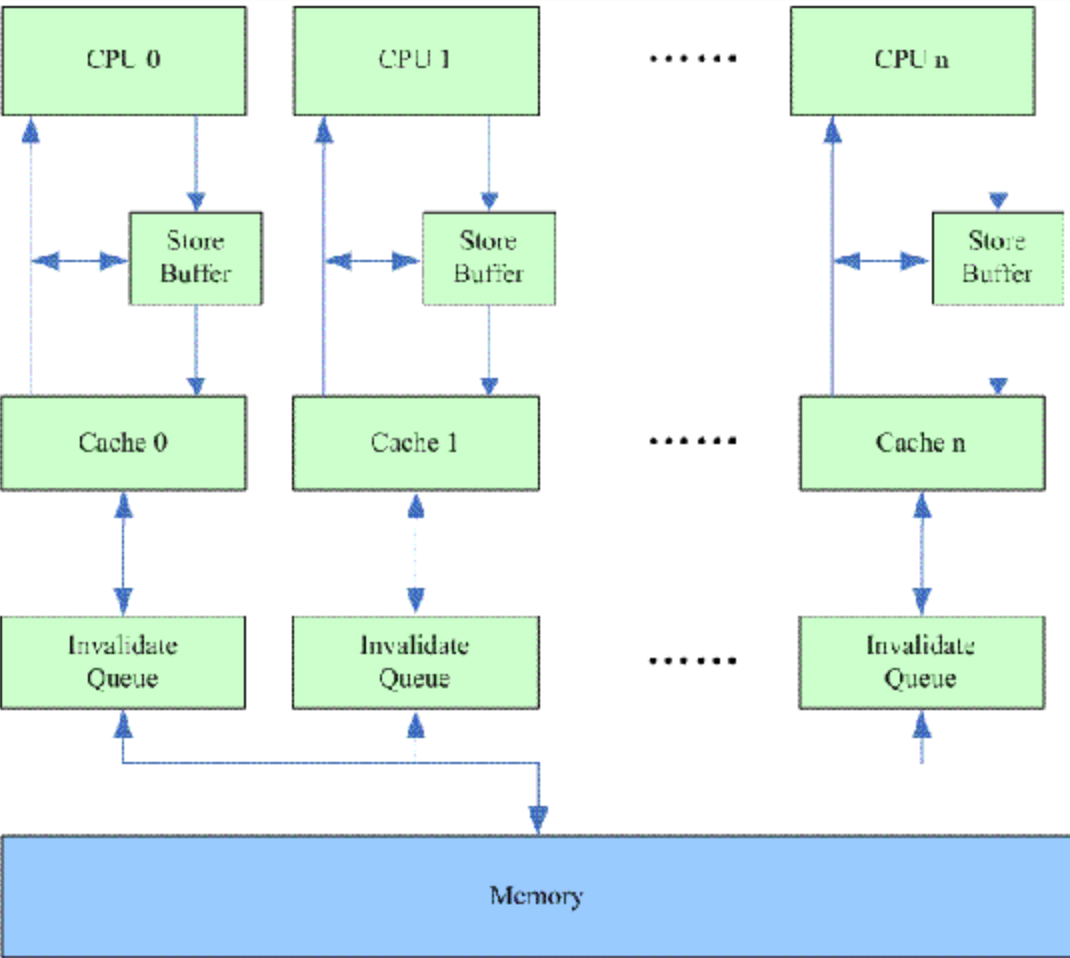
- 收到失效消息时,放到失效队列中去。
- 为了不让处理器久等失效响应,收到失效消息需要马上回复失效响应。
- 为了不频繁阻塞处理器,不会马上读主存以及设置缓存为invlid,合适的时候再一块处理失效队列。
happens- before原则
虽然指令重排提高了并发的性能,但是Java虚拟机会对指令重排做出一些规则限制,并不能让所有的指令都随意的改变执行位置,主要有以下几点:
1、单线程每个操作,happen-before于该线程中任意后续操作;
2、volatile写happen-before与后续对这个变量的读;
3、synchronized解锁happen-before后续对这个锁的加锁;
4、final变量的写happen-before于final域对象的读,happen-before后续对final变量的读;
5、传递性规则,A先于B,B先于C,那么A一定先于C发生;
https://www.processon.com/view/5c8b0978e4b0c996d363dcbc?fromnew=1